
[BERT4Rec] Sequential Recommendation with Bidirectional Encoder Representations from Transformer
Introduction
Uni-directional 모델(SASRec & RNN-based methods)은 users’ behavior sequences를 파악하기 충분하지 않을 수 있습니다. 왜냐하면 user의 historical interaction에서 일어난 과정에 순서가 있다고 말을 할 수 없기 떄문입니다. 예를 들어, 어느 user가 Nintendo Switch(게임기 본체)를 구매한 다음 Joy-Con(게임 조작기)를 구매할 수 있고, 그 반대가 될 수 있도 있습니다. 따라서, 어떤 것이 먼저 오는지는 그렇게 중요하지 않을 수 있습니다. 이처럼 저자는 user의 historical pattern을 Uni-directional으로만 학습하는 것은 현실적이지 않을 수 있다고 지적하며 Bi-directional 학습 모델인 BERT4Rec을 제안합니다.
BERT4Rec
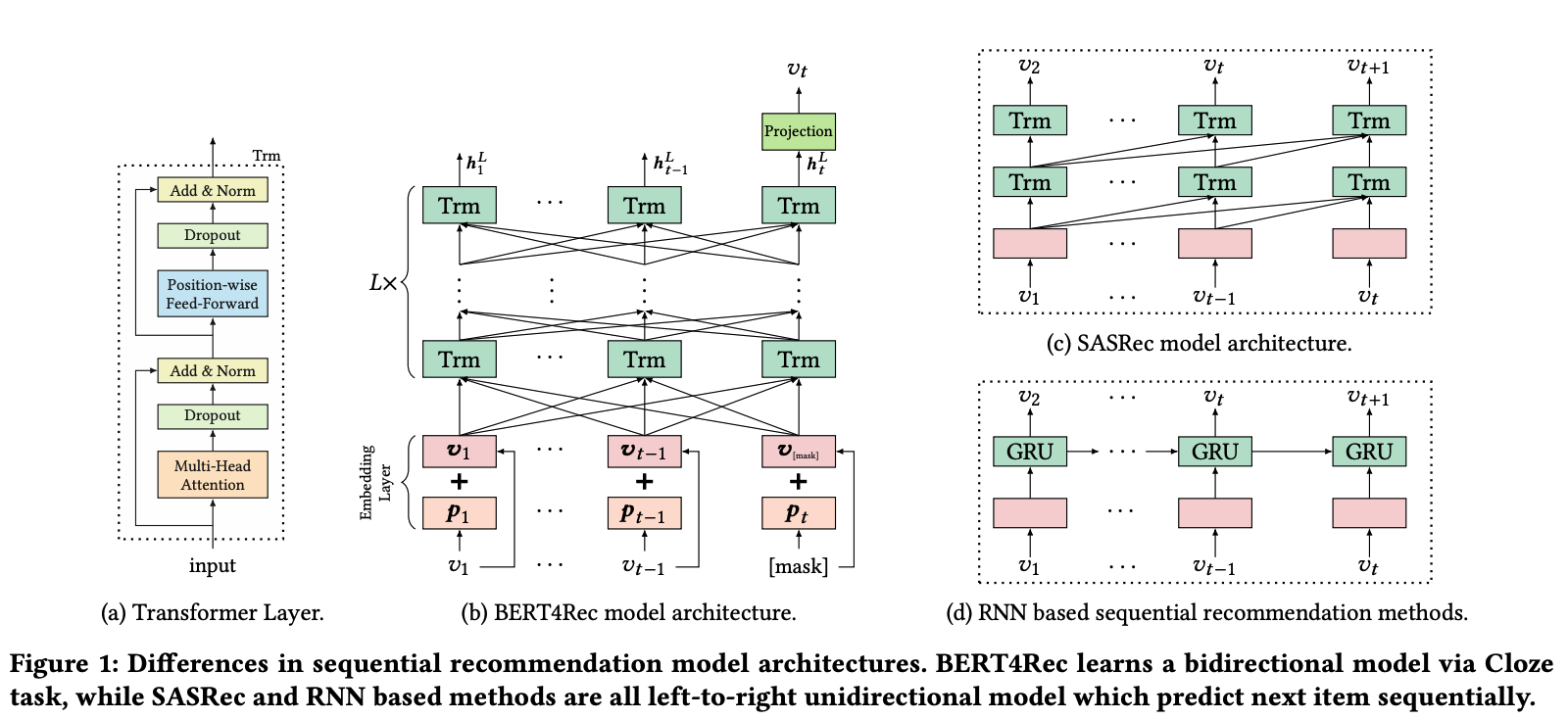
BERT4Rec 모델은 Embedding Layer (positional & item), Transformer Layer, Output Layer로 구성됩니다. 모델을 Bi-directional으로 학습하기 위해 BERT의 학습 방법과 같이 사용자 행동 시퀀스에 대해 [Mask] 토큰을 사용하여 앞뒤 정보에서 [Mask] 정보를 파악할 수 있도록 합니다(Cloze Task). 이렇게 [Mask]를 사용하는 이유는 모델이 Bi-directional으로 학습하는 동안 target 항목의 정보를 직접 보게 되어 Information Leakage가 발생할 수 있기 때문입니다.
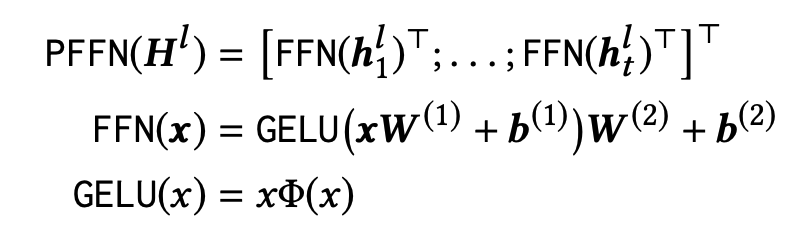
Transformer Layer의 경우 기존 Transformer와 동일하게 Multi-head Attention(MH) 와 Point-wise Feed Forward Network(PFFN)를 사용하며 레이어의 수 L만큼 반복 연산을 수행하게 됩니다. 본 논문에서는 PFFN의 activation function으로 smoother GELU를 사용했습니다.
학습 과정은 Cloze task(일부 단어가 제거된 언어의 일부를 채우는 작업)를 sequential recommendation에 적용함으로써 진햅합니다. 그리고 각 훈련 단계에서 모든 item중 p%를 무작위로 마스킹하고, 주어진 정보로만 masking된 부분의 id를 예측합니다.
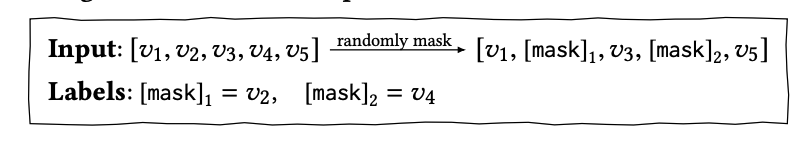
입력 시퀀스: "I like to eat [mask] and [mask]."
마스킹된 항목: "apple"과 "banana"
예측된 id: 1과 2
모델의 Loss의 경우 Negative log-likelihood를 사용하여 [Mask]가 반영된 유저의 행동 시퀀스($S^{′}_{u}$)가 주어졌을 때 [Mask] 아이템($v_m$)과 실제 [Mask]의 아이템($v ∗ m$)을 비교하여 낮은 확률을 가질록 weight를 더 많이 업데이트하는 방식으로 학습이 진행되고, 모델은 Loss을 최소화하는 방향으로 학습되므로 실제 아이템의 확률을 더 높이 예측하는 방법을 학습합니다.
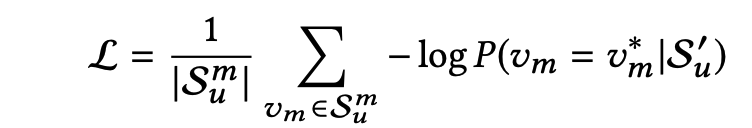
Experiments
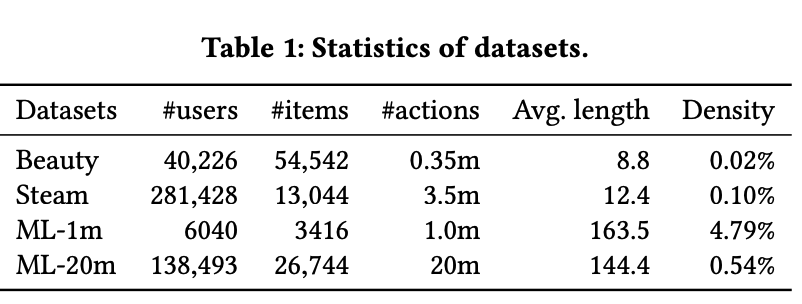
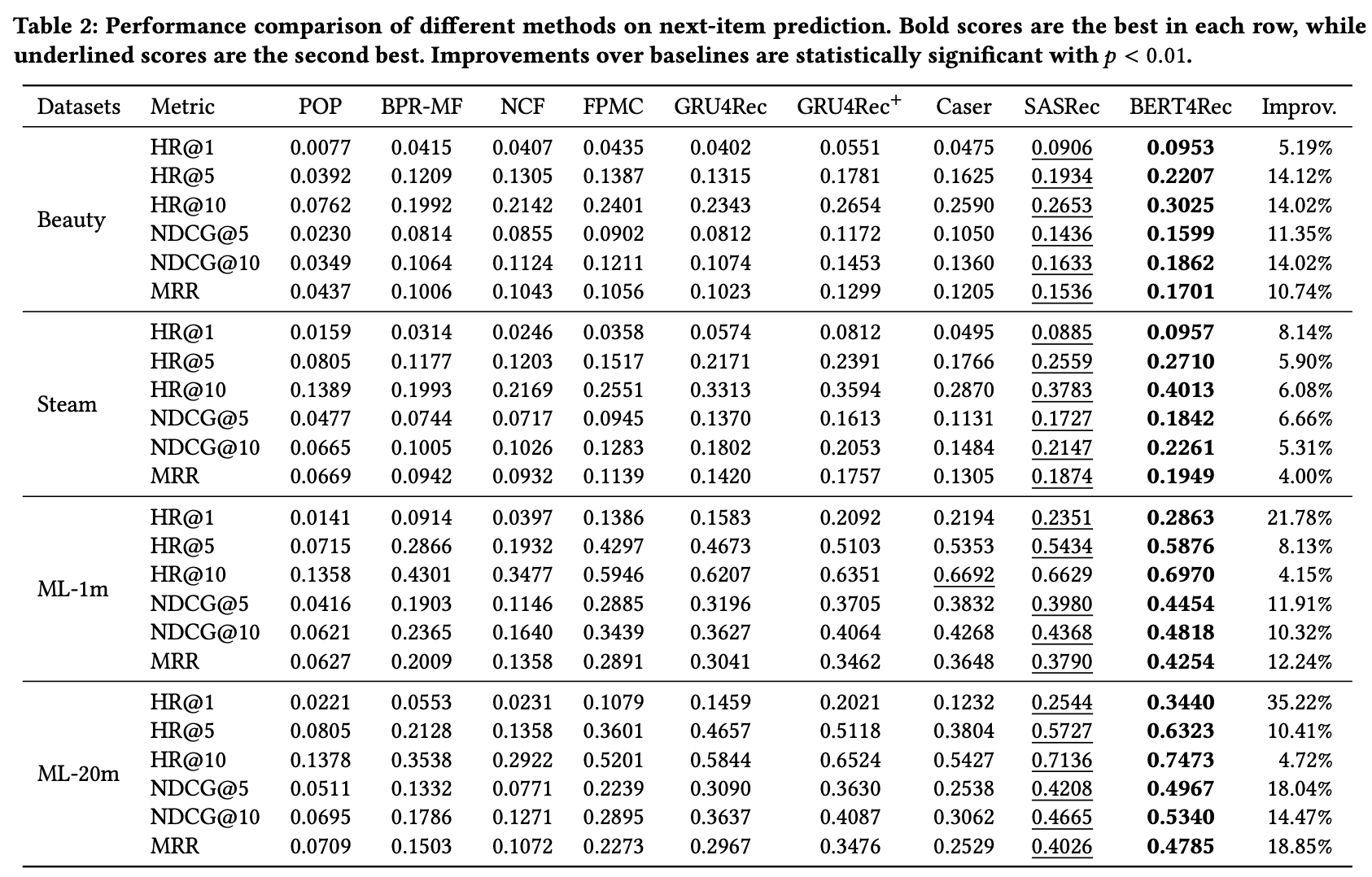
BERT4Rec은 모든 데이터 세트에서 가장 높은 성능을 달성하여 제안된 모델이 사용자 행동에 대한 양방향 학습이 더 나은 추천을 생성할 수 있음을 보여줍니다. SASRec도 이전의 순차 추천 모델보다 성능이 우수하지만 BERT4Rec만큼 좋지는 않습니다. 이 결과는 Bi-directional이 Uni-directional보다 사용자 행동에 대한 더 나은 표현을 제공할 수 있음을 시사합니다
Reference:
- https://arxiv.org/pdf/1904.06690.pdf
- https://github.com/SeongBeomLEE/RecsysTutorial/blob/main/BERT4Rec/BERT4Rec.ipynb
- https://greeksharifa.github.io/machine_learning/2021/12/12/Bert4Rec/
- https://dhgudxor.tistory.com/9