
[LSTF-Linear] Are Transformers Effective for Time Series Forecasting
Introduction
최근 Transformer 기반 모델은 Long-Term Time Series Forecasting에서 기존의 Non-Transformer 기반 방법론보다 정확도가 우수한 것으로 나타났습니다. 그러나 이러한 실험에서 기존의 베이스라인 모델은 Autoregressive 방식으로 예측되었으며, 이는 Error Accumulation Effect를 유발할 수 있으므로 성능이 좋지 않을 수밖에 없습니다.
Transformer 구조의 핵심은 Multi-Head Self Attention입니다. 이 구조는 Long Sequence에서 Paired Element 간의 잠재적인 상관관계를 추출하는 데 효과적이지만, 시간 순서를 고려하지 않고 있습니다. 시계열 데이터 분석의 경우 입력 데이터의 순서가 연속적인 지점 사이에 존재하는 Temporal Dynamics를 찾는 데 중요한 역할을 하기 때문에 Multi-Head Self Attention의 동작 원리를 고려할 때 Transformer가 시계열 데이터 분석에 효과적인지 질문할 필요가 있습니다.
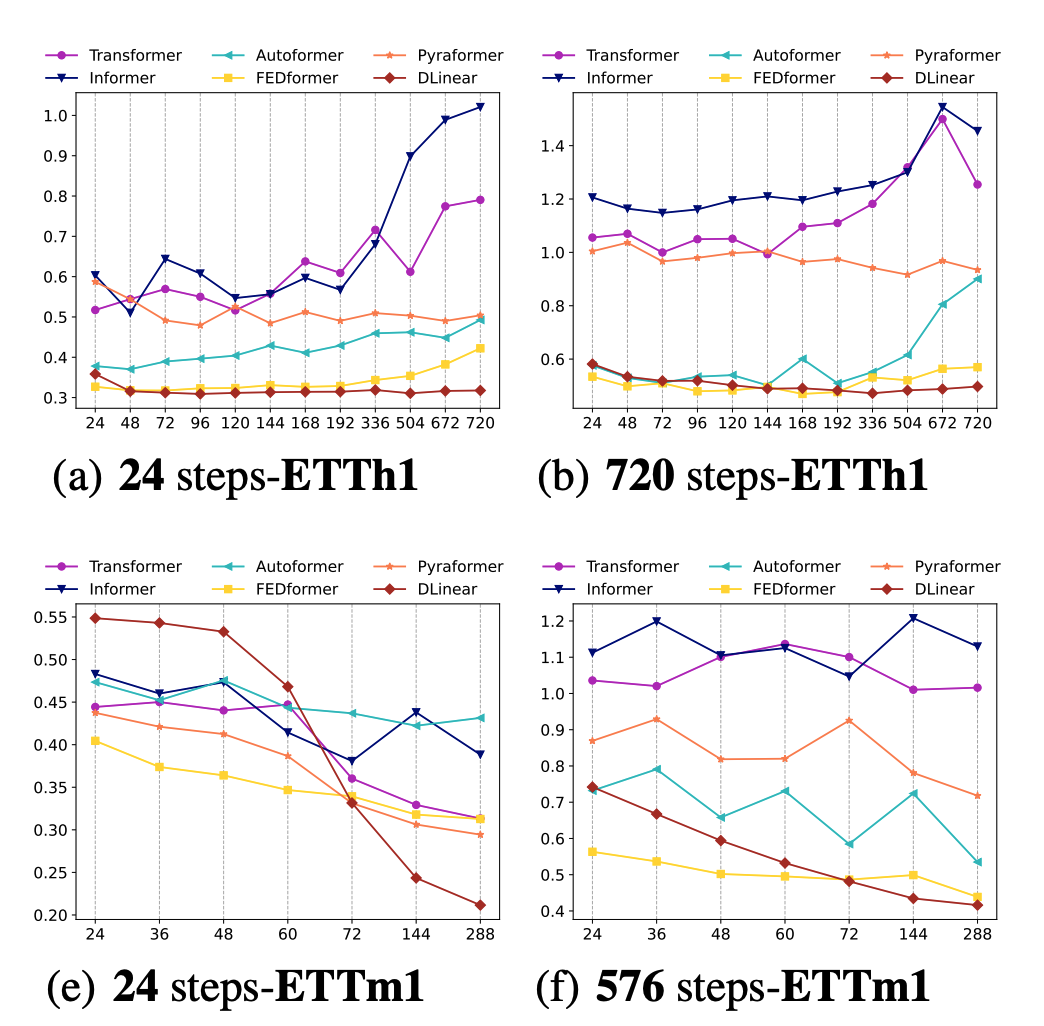
본 논문은 Transformer 기반 모델에서 Lookback Window의 크기를 늘릴수록 예측 오류가 감소해야 하지만 그렇지 않은 현상, 심지어 Lookback Window의 크기를 늘렸음에도 예측 오류가 증가하는 현상을 지적합니다. 그리고 저자는 Transformer와 같이 복잡한 모델을 사용하지 않고 단순히 2개의 1-Layer Linear Network만을 사용하는 모델을 제안하고, 여러 LTSF 벤치마크 데이터 세트에서 제안된 모델이 기존 모델을 능가하는 것을 실험을 통해 보이고자 합니다.
위와 같은 내용으로 간단한 선형 모델이 Long Term 시계열 데이터에서 시간 순서 정보를 보존하면서 추세와 주기성에 대한 특징을 더 잘 추출할 수 있기 때문에 LTSF-Linear(Linear, DLinear, NLinear) 모델을 제안했습니다. 해당 모델은 단순한 단일 선형 레이어로 구성되었지만 9개의 벤치마크 데이터 세트에서 기존의 Transformer 기반 모델보다 우수한 성능을 보여줬습니다.
Models
1. DLinear
DLinear 모델은 Autoformer와 FEDformer 모델에서 사용되는 시계열 분해 방식을 선형 레이어와 결합한 모델입니다. 먼저 이동 평균을 계산한 다음 이를 제거하여 추세와 주기성 데이터로 분해합니다. 그런 다음 각 구성 요소에 단일 선형 레이어를 적용하고 두 개를 합산하여 최종 예측을 계산합니다. 이 모델은 시계열 데이터에 명확한 추세와 주기성이 있을 때 기존 선형 모델보다 더 나은 성능을 발휘할 수 있습니다.
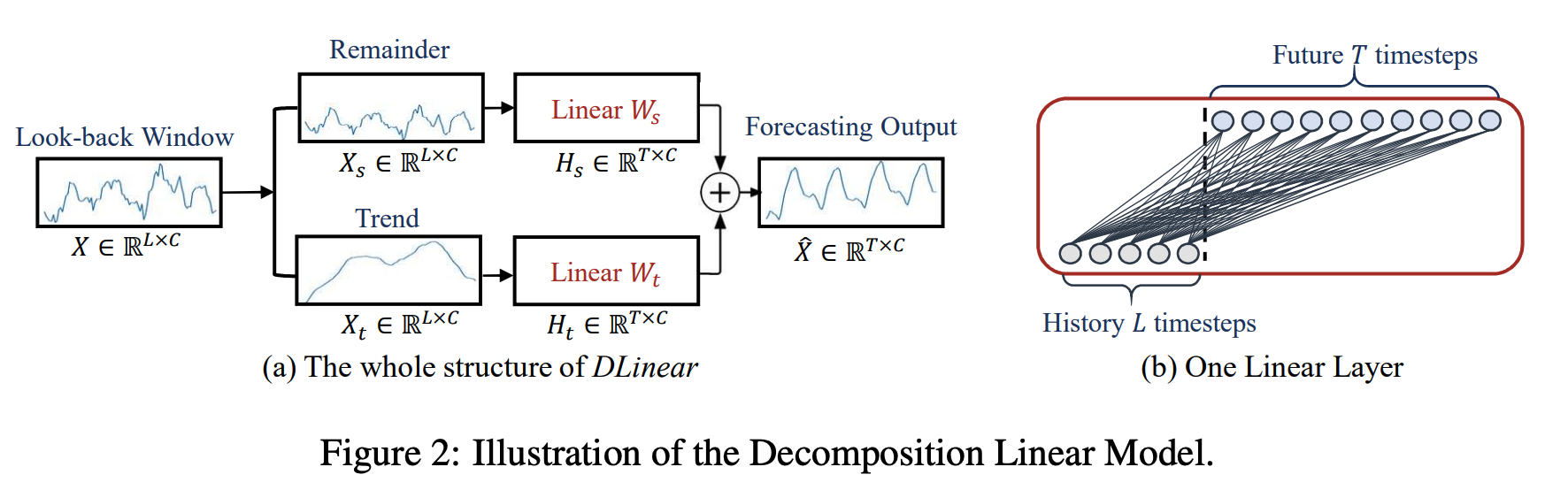
2. NLinear
NLinear 모델은 선형 모델의 변형으로, 가장 마지막 값을 뺀 후 모델을 학습하고 가장 마지막에 다시 더하여 예측을 계산합니다. 이렇게 하면 분포 이동이 방지되어 학습 데이터와 평가 데이터 간의 분포가 일치하지 않기 때문에 발생할 수 있는 예측 오류를 방지할 수 있습니다. 이러한 개선으로 NLinear 모델은 ETth1, ETth2 및 ILI 벤치마크 데이터셋에 대해 우수한 성능을 달성했습니다.
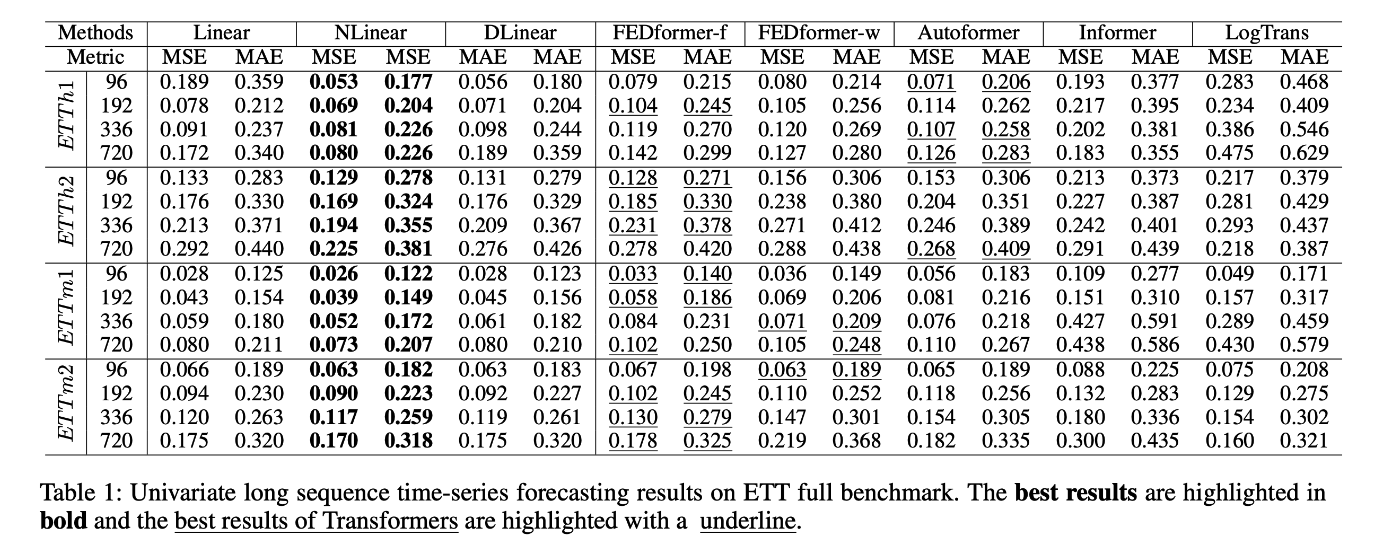
이외에도 하나의 레이어를 갖고 있는 Linear 모델이 Transformer 시계열 모델보다 성능이 좋다는 것을 실험적으로 확인했습니다.
LSTF-Linear 알고리즘 Pytorch
import torch
import pyupbit
import torch.nn as nn
from torch.nn import functional as F
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
class moving_avg(nn.Module):
"""
Moving average block to highlight the trend of time series
"""
def __init__(self, kernel_size, stride):
super(moving_avg, self).__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=stride, padding=0)
def forward(self, x):
# padding on the both ends of time series
front = x[:, 0:1, :].repeat(1, (self.kernel_size - 1) // 2, 1)
end = x[:, -1:, :].repeat(1, (self.kernel_size - 1) // 2, 1)
x = torch.cat([front, x, end], dim=1)
x = self.avg(x.permute(0, 2, 1))
x = x.permute(0, 2, 1)
return x
class series_decomp(nn.Module):
"""
Series decomposition block
"""
def __init__(self, kernel_size):
super(series_decomp, self).__init__()
self.moving_avg = moving_avg(kernel_size, stride=1)
def forward(self, x):
moving_mean = self.moving_avg(x)
res = x - moving_mean
return res, moving_mean
class Dlinear(nn.Module):
"""
D-Linear
"""
def __init__(self, window_size, forcast_size, feature_size=4, kernel_size=25, individual=False):
super(Dlinear, self).__init__()
# Decompsition Kernel Size
self.seq_len = window_size
self.pred_len = forcast_size
self.channels = feature_size
self.decompsition = series_decomp(kernel_size)
self.individual = individual
if self.individual:
self.Linear_Seasonal = nn.ModuleList()
self.Linear_Trend = nn.ModuleList()
for i in range(self.channels):
self.Linear_Seasonal.append(nn.Linear(self.seq_len,self.pred_len))
self.Linear_Trend.append(nn.Linear(self.seq_len,self.pred_len))
else:
self.Linear_Seasonal = nn.Linear(self.seq_len,self.pred_len)
self.Linear_Trend = nn.Linear(self.seq_len,self.pred_len)
def forward(self, x):
# x: [Batch, Input length, Channel]
seasonal_init, trend_init = self.decompsition(x)
seasonal_init, trend_init = seasonal_init.permute(0,2,1), trend_init.permute(0,2,1)
if self.individual:
seasonal_output = torch.zeros([seasonal_init.size(0),seasonal_init.size(1),self.pred_len],dtype=seasonal_init.dtype).to(seasonal_init.device)
trend_output = torch.zeros([trend_init.size(0),trend_init.size(1),self.pred_len],dtype=trend_init.dtype).to(trend_init.device)
for i in range(self.channels):
seasonal_output[:,i,:] = self.Linear_Seasonal[i](seasonal_init[:,i,:])
trend_output[:,i,:] = self.Linear_Trend[i](trend_init[:,i,:])
else:
seasonal_output = self.Linear_Seasonal(seasonal_init)
trend_output = self.Linear_Trend(trend_init)
x = seasonal_output + trend_output
return x.permute(0,2,1) # to [Batch, Output length, Channel]
class LTSF_Linear(torch.nn.Module):
def __init__(self, window_size, forcast_size, individual, feature_size = 4, individual=False):
super(LTSF_Linear, self).__init__()
self.window_size = window_size
self.forcast_size = forcast_size
self.individual = individual
self.channels = feature_size
if self.individual:
self.Linear = torch.nn.ModuleList()
for i in range(self.channels):
self.Linear.append(torch.nn.Linear(self.window_size, self.forcast_size))
else:
self.Linear = torch.nn.Linear(self.window_size, self.forcast_size)
def forward(self, x):
if self.individual:
output = torch.zeros([x.size(0),self.pred_len,x.size(2)],dtype=x.dtype).to(x.device)
for i in range(self.channels):
output[:,:,i] = self.Linear[i](x[:,:,i])
x = output
else:
x = self.Linear(x.permute(0,2,1)).permute(0,2,1)
return x
class Nlinear(torch.nn.Module):
def __init__(self, window_size, forcast_size, feature_size=4, individual=False):
super(Nlinear, self).__init__()
self.window_size = window_size
self.forcast_size = forcast_size
self.channels = feature_size
self.individual = individual
if self.individual:
self.Linear = torch.nn.ModuleList()
for i in range(self.channels):
self.Linear.append(torch.nn.Linear(self.window_size, self.forcast_size))
else:
self.Linear = torch.nn.Linear(self.window_size, self.forcast_size)
def forward(self, x):
seq_last = x[:,-1:,:].detach()
x = x - seq_last
if self.individual:
output = torch.zeros([x.size(0), self.forcast_size, x.size(2)],dtype=x.dtype).to(x.device)
for i in range(self.channels):
output[:,:,i] = self.Linear[i](x[:,:,i])
x = output
else:
x = self.Linear(x.permute(0,2,1)).permute(0,2,1)
x = x + seq_last
return x
def targetParsing(data,target,index=False):
if index==False:
result=data.loc[:,target]
else:
result=data.iloc[:,target]
return list(result.index), result.to_numpy()
def transform(raw,check_inverse=False):
data=raw.reshape(-1,1)
if check_inverse==False:
return scaler.fit_transform(data)
else:
return scaler.inverse_transform(data)[:,0]
class windowDataset(Dataset):
def __init__(self, y, input_window, output_window, stride=1):
#총 데이터의 개수
L = y.shape[0]
#stride씩 움직일 때 생기는 총 sample의 개수
num_samples = (L - input_window - output_window) // stride + 1
#input과 output
X = np.zeros([input_window, num_samples])
Y = np.zeros([output_window, num_samples])
for i in np.arange(num_samples):
start_x = stride*i
end_x = start_x + input_window
X[:,i] = y[start_x:end_x]
start_y = stride*i + input_window
end_y = start_y + output_window
Y[:,i] = y[start_y:end_y]
X = X.reshape(X.shape[0], X.shape[1], 1).transpose((1,0,2)) #X:(num_samples,input_window,1)
Y = Y.reshape(Y.shape[0], Y.shape[1], 1).transpose((1,0,2)) #Y:(num_samples,output_window,1)
self.x = X
self.y = Y
self.len = len(X)
def __getitem__(self, i):
return self.x[i], self.y[i]
def __len__(self):
return self.len
def customDataLoader(data,window_size:int,forecast_size:int,batch_size:int):
train=transform(data)[:-window_size,0]
dataset=windowDataset(train,window_size,forecast_size)
result=DataLoader(dataset,batch_size=batch_size)
return result
class trainer():
def __init__(self, data, dataloader, window_size, forecast_size, name="DLinear", feature_size=4, lr=1e-4):
self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
self.data=data
self.trains=transform(data)[:-window_size,0]
self.dataloader=dataloader
self.window_size=window_size
self.forecast_size=forecast_size
if name=="DLinear":
self.model=Dlinear(window_size,forecast_size).to(self.device)
elif name == "NLinear":
self.model=Nlinear(window_size,forecast_size).to(self.device)
else:
self.model=LSTF_Linear(window_size,forecast_size).to(self.device)
self.feature_size=feature_size
self.name=name
self.criterion = nn.MSELoss()
self.optimizer=torch.optim.Adam(self.model.parameters(), lr=lr)
def train(self, epoch=100):
self.model.train()
progress=tqdm(range(epoch))
losses=[]
for i in progress:
batchloss = 0.0
for (inputs, outputs) in self.dataloader:
self.optimizer.zero_grad()
result = self.model(inputs.float().to(self.device))
loss = self.criterion(result, outputs.float().to(self.device))
loss.backward()
self.optimizer.step()
batchloss += loss
losses.append(batchloss.cpu().item())
progress.set_description("loss: {:0.6f}".format(batchloss.cpu().item() / len(self.dataloader)))
plt.plot(losses)
def evaluate(self):
window_size=self.window_size
input = torch.tensor(self.trains[-window_size:]).reshape(1,-1,1).float().to(self.device)
self.model.eval()
predictions = self.model(input)
return predictions.detach().cpu().numpy()
def implement(self):
process=trainer(self.data,self.dataloader,self.window_size,
self.forecast_size,self.feature_size,self.name)
process.train()
evaluate=process.evaluate()
result=transform(evaluate,check_inverse=True)
return result
def figureplot(date,data,pred,window_size,forecast_size):
datenum=mdates.date2num(date)
len=data.shape[0]
fig, ax = plt.subplots(figsize=(20,5))
ax.plot(datenum[len-window_size:len], data[len-window_size:], label="Real")
ax.plot(datenum[len-forecast_size:len], pred, label="LSTF-linear")
locator = mdates.AutoDateLocator()
formatter = mdates.AutoDateFormatter(locator)
ax.xaxis.set_major_locator(locator)
ax.xaxis.set_major_formatter(formatter)
plt.legend()
plt.show()
scaler=MinMaxScaler()
raw = pyupbit.get_ohlcv(ticker='KRW-BTC',interval='minute15', count = 500)
window_size=128
forecast_size= 10
date, data =targetParsing(raw,'close') # preprocess raw data
dataloader=customDataLoader(data, window_size,forecast_size, batch_size=4) #make dataloader
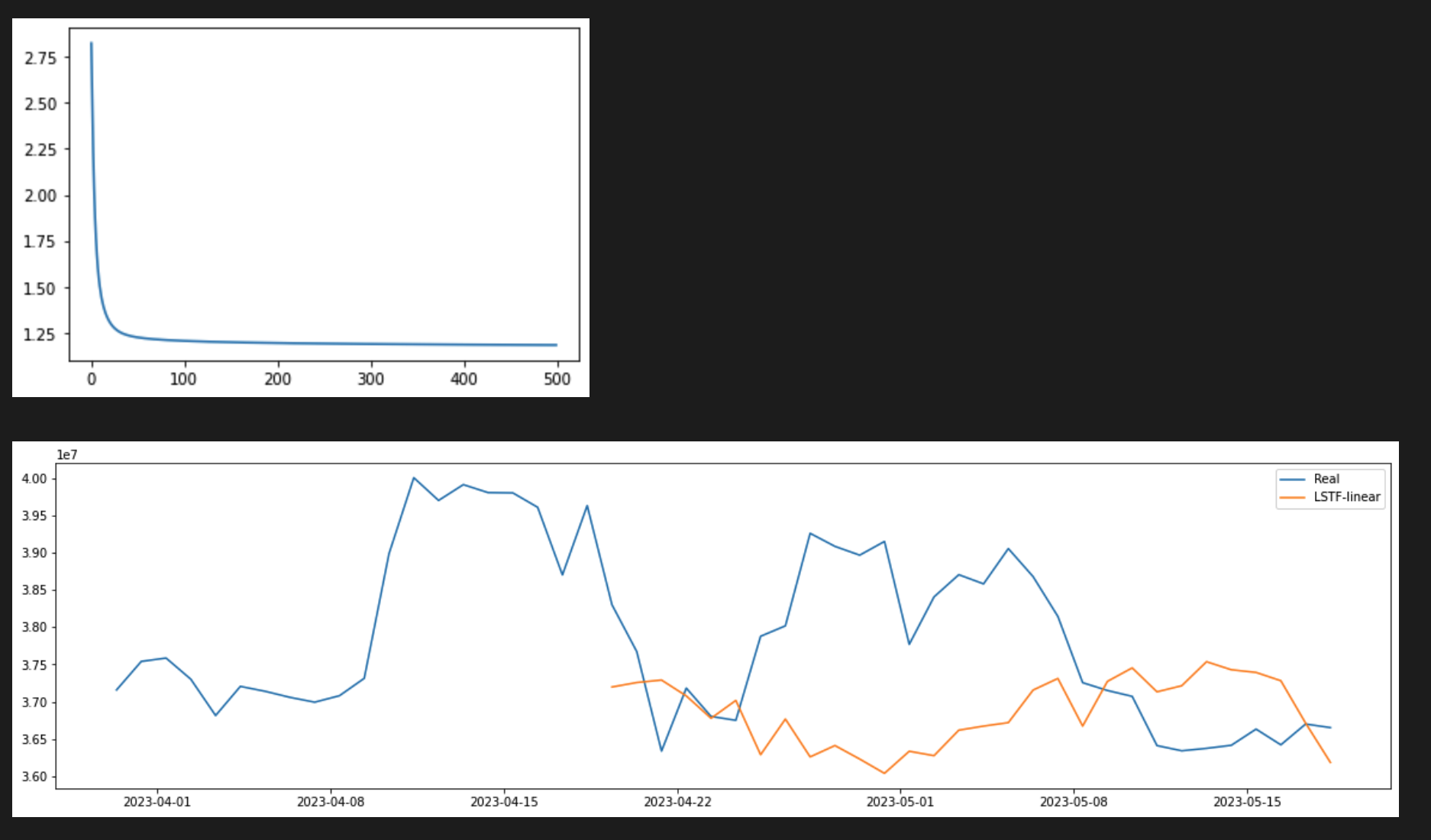
pred=trainer(data, dataloader, window_size, forecast_size, name="NLinear").implement() #train and evaluate
figureplot(date,data,pred,window_size,forecast_size) #plot the result
Reference:
- https://github.com/cure-lab/LTSF-Linear
- https://arxiv.org/pdf/2205.13504v2.pdf