
[DeText] A Deep Neural Text Understanding Framework
Introduction
검색 엔진의 랭킹 모델이 쿼리의 Contextual Information 잘 이해하려면 BERT와 같은 언어 모델을 사용해야 하는데, 이와 같은 알고리즘을 바로 사용할 경우 계산 비용이 크다는 문제가 있습니다 (대량의 트래픽이 발생하고 Response Time이 중요한 서비스는 latency가 중요함). 그래서 본 논문에서는 이 문제를 개선시키는 BERT 기반의 검색 Framework(aka DeText)을 제안합니다.
DeText 에서는 사용자는 사용 목적에 따라 NLP 모델을 바꿔 활용하여 검색 및 추천 시스템을 이전보다 더 좋게 만들 수 있습니다. 예를 들어 LinkedIn에서 우리는 LiBERT(LinkedIn 데이터로 훈련된 BERT)를 사용하여 텍스트 쿼리 뒤에 있는 의미를 더 잘 이해하고 검색에서 사용자 의도를 포착할 수 있습니다.
DeText 프레임워크의 장점은 다음과 같습니다.
- 최첨단 의미 이해 모델(CNN/LSTM/BERT) 지원
- 효율성과 효과성 사이의 균형
- 모듈 구성에 대한 유연성 제공
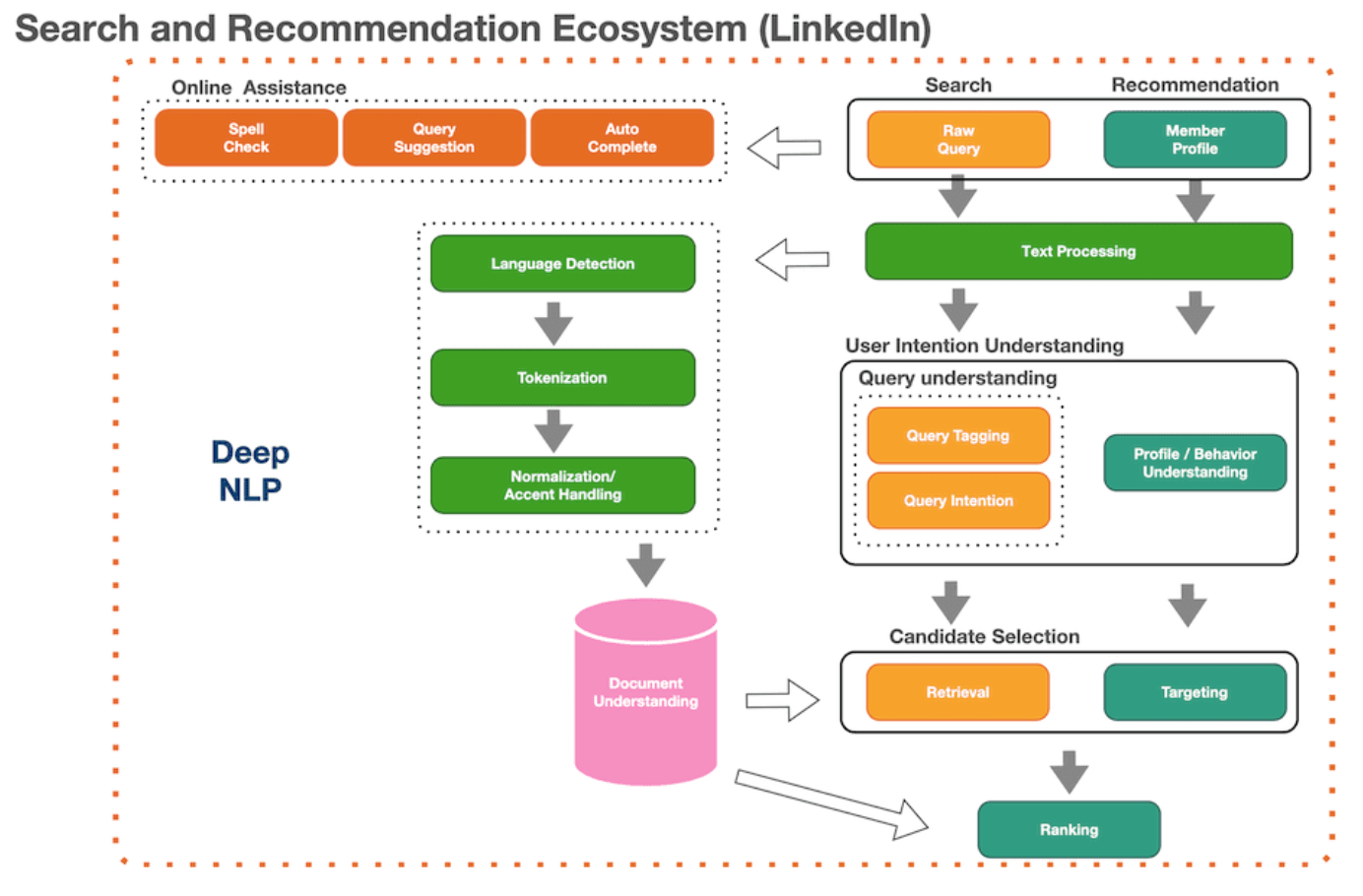
DeText Architecture
-
Input text data: 입력 텍스트 데이터는 소스와 대상 텍스트로 일반화됩니다. 소스는 검색 시스템의 쿼리이거나 추천 시스템의 사용자 프로필일 수 있습니다. 대상은 문서일 수 있습니다. 소스와 대상 모두 여러 필드를 가질 수 있습니다.
-
Word embedding layer: 단어 시퀀스가 임베딩 행렬로 변환됩니다. 정확히는 입력 텍스트에 대한 임베딩 단계입니다. m은 토큰이고 d는 임베딩 차원으로 임베딩은 d x m 메트릭스입니다. CNN과 LSTM은 개별 단어를 입력으로 사용하지만 BERT는 Subwords를 입력으로 사용합니다.
-
Text embedding layer: DeText는 CNN/LSTM/BERT를 활용하여 텍스트 임베딩을 추출합니다. CNN/LSTM은 Low Latency 제공하는 Lightweight 솔루션으로 제공됩니다. Complicated Semantic Meanings 추출이 필요한 경우 BERT를 사용할 수 있습니다.
-
Interaction layer: Source과 Target 임베딩에서 Deep Features을 계산하기 위해 여러 상호 작용 방법이 있습니다. Cosine Similarity, Harmard Product, Concatenation 등.
-
Traditional feature processing: Hand-crafted traditional features에 특성 정규화 및 요소별 재조정(rescaling)이 적용됩니다. 학습에 참여하는 Feature들 중에서 Text를 제외하고 특정 도메인에 knowledge가 있습니다. 이런 domain knowledge를 이용해서 다양한 Feature를 만들고 이를 학습에 사용하는 단계입니다. Traditional feature의 예로는 Personalization features, Social networks, User behavior features가 있습니다.
-
MLP layer: Interaction layer(deep features)와 traditional features을 연결하고, 두 features 사이의 non-linearity을 학습합니다.
-
LTR layer: Learning to Rank을 학습하는 단계입니다. Pointwise, Pairwise, Listwise, 또는 LambdaRank을 목적에 맞게 선택해서 사용하면 됩니다. 상대적인 위치가 중요하면 pairwise, listwise를 사용하고, 그렇지 않으면 pointwise를 사용하게 됩니다.
Strategy for Deployment
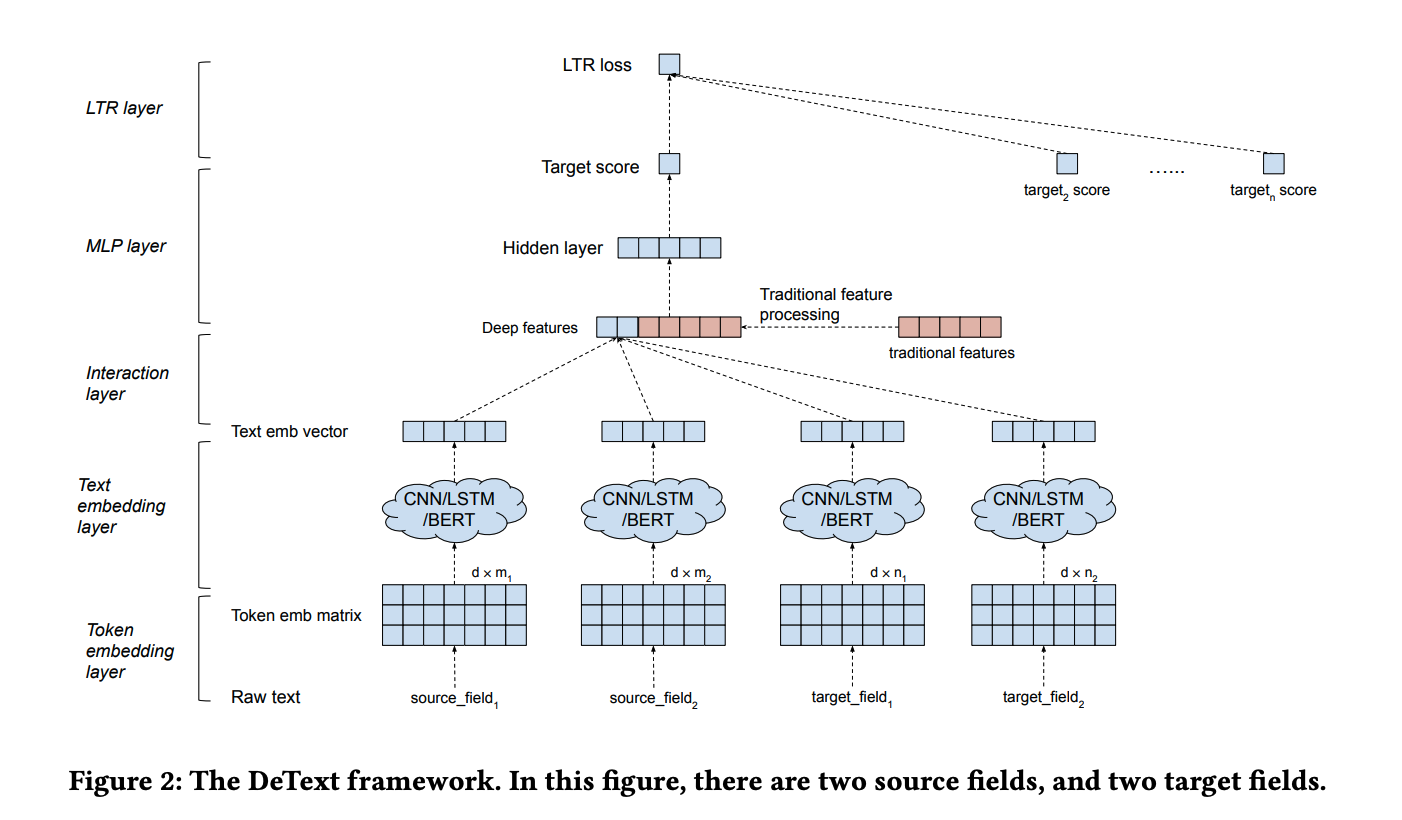
검색 시스템에서 딥 러닝 모델을 적용할 때는 두 가지 주요 문제가 있습니다. 첫 번째 문제는 BERT는 파라미터가 많아서 즉시 서비스하기에는 부담스러운 모델이라는 것입니다. 두 번째 문제는 문서의 수가 많을수록 계산 비용이 선형적으로 증가한다는 것입니다.
본 논문에서는 이 문제를 해결하기 위해 two deployment strategies을 제안합니다. 첫 번째 전략은 계산 비용을 줄이기 위해 BERT를 사용하여 문서 임베딩을 사전 계산하고 키가 document_id, 값이 사전 계산된 문서 임베딩 벡터인 key-value 형태로 저장하는 방법입니다 (정기적으로 업데이트해줘야 함). 그러면 document_id에 해당하는 vector가 있어서 그 embedding vector을 DeText 모델에 보내서 순위를 추출하기만 하면 됩니다.
두 번째 전략은 문서가 증가하면 할수록 계산 비용이 증가하는 문제에 대한 전략입니다. 이 전략에서는 Retrieveal 단계는 동일하게 유지되지만 랭킹 부분에서는 two-pass 랭킹 전략을 사용합니다. 첫 번째 단계에서는 traditioanl features만 사용하여 MLP를 수행하고, Top-k개의 문서를 추출한 다음 두 번째 단계에서 DeText-CNN 모델을 통해 문서의 ranking을 추출하는 것입니다.
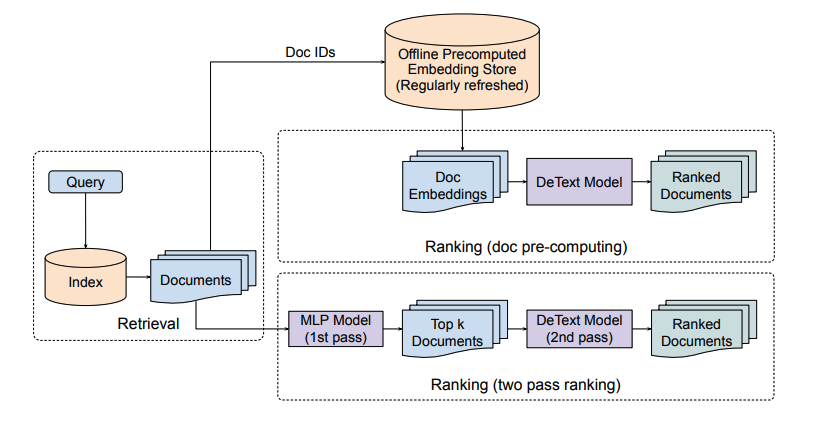
Reference:
- https://arxiv.org/pdf/2008.02460.pdf
- https://engineering.linkedin.com/blog/2020/open-sourcing-detext
- https://www.youtube.com/watch?v=tE_1uiaUf1k