
[Transformer] Attention Is All You Need
Introduction
RNN, LSTM, 그리고 GRU 활용 모델은 기계번역 등의 문제에서 뛰어난 성과를 보였다. 하지만 RNN 계열 모델은 재귀적인 특성 때문에 병렬 처리 연산이 불가능하다는 것이 치명적인 단점이다. 그러면 RNN의 어떤 점이 재귀적인 것일까? RNN 계열 모델은 이전 단계에서 계산한 $h_{t-1}$ 로 현 단계의 $h_t$ 를 순차적으로 생성하는 부분이 재귀적인 특성을 보여준다. 따라서 RNN 계층의 순환 구조가 연산을 병렬화할 수 없게 만든다. 그리고 RNN 계열 모델은 또 한가지의 문제점이 존재한다. 입력과 출력 간의 대응되는 단어들 사이의 거리가 멀수록 그 관계를 모델이 잘 학습하지 못한다 (Long-term dependency problem). 이러한 단점을 보완하고자 seq2seq 구조에서의 Attention만을 사용하는 것을 바로 Transformer 라고한다.
Transformer Architecture
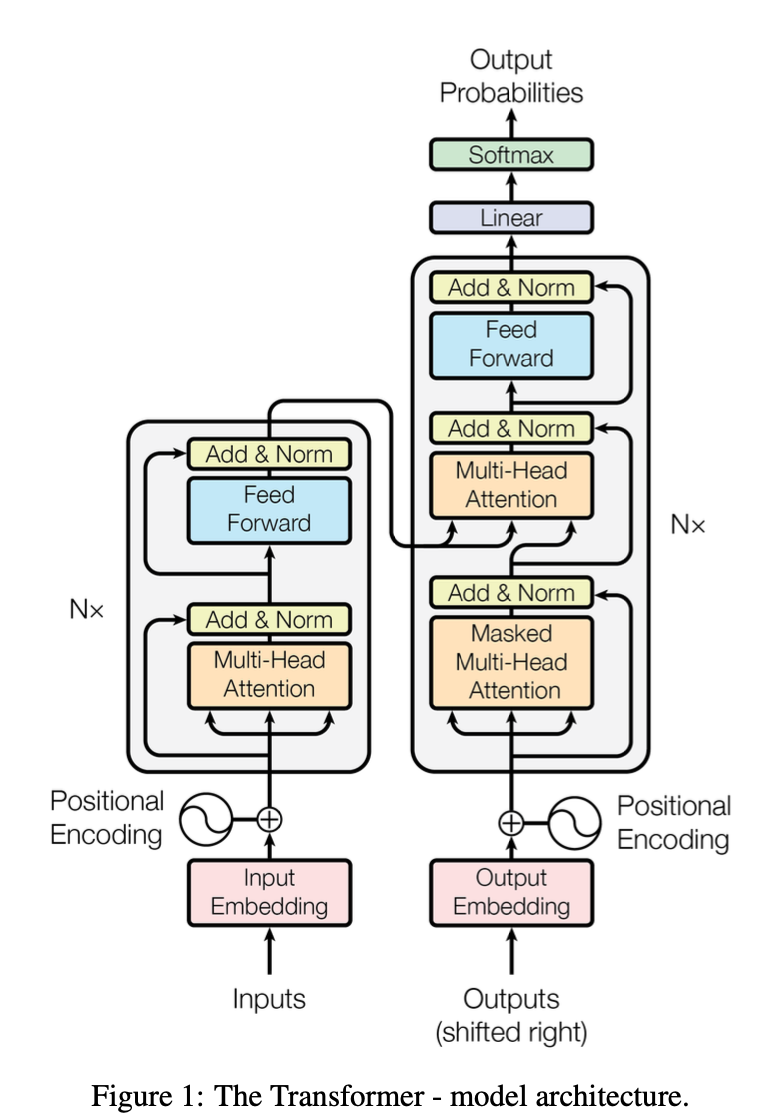
지금까지의 Transduction (변환) 모델은 대부분 RNN 계열의 encoder-decoder 구조를 가지고 있는 반면, Transformer은 encoder-decoder 구조를 사용하지만 그 내부는 attention 과 point-wise feed forward network 만으로 구성되어 있다.
Encoder-Decoder Stacks
Encoder는 동일한 레이어의 구성으로 6개가 stacked 되어있고, 각 레이어는 아래 2개의 서브레이어로 이루어져 있다.
- Multi-head self-attention
- position-wise fully connected feed-forward network
각 서브레이어의 출력값은 $LayerNorm(x + SubLayer(x))$ 으로 skip connection 과 normalization 을 적용했다.
Decoder은 6개의 동일한 레이어로 stacked 되어있지만, 3 개의 서브레이어로 이루어져 있다.
- Multi-head self-attention
- Masked Multi-head self-attention
- position-wise fully connected feed-forward network
Encoder와 동일하게 skip connection와 normalization을 사용하고, Decoder가 출력값을 생성할 때 다음 출력(미래)에서 정보를 얻는 것을 방지하기 위해 masking을 사용한다.
Attention & Multi-head Attention
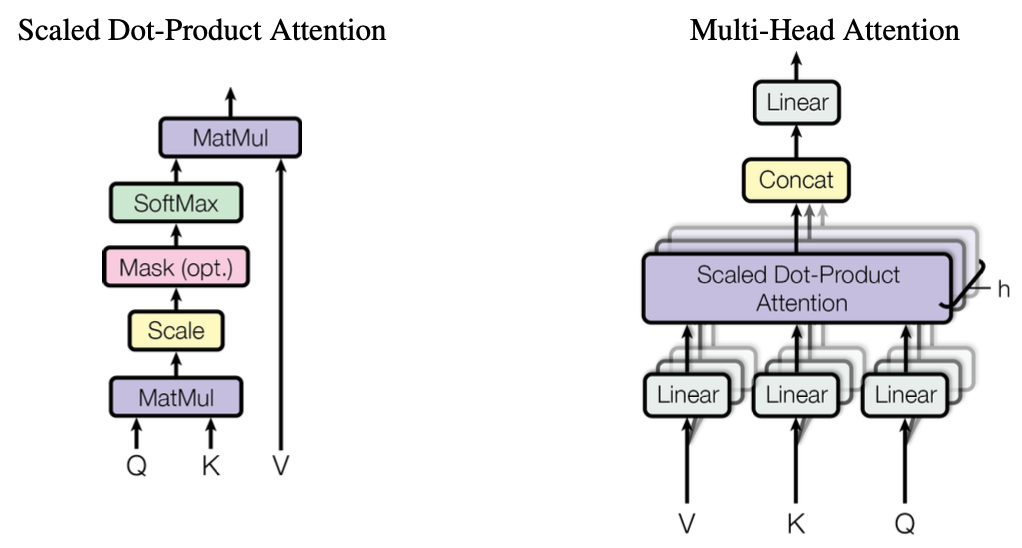
Scaled Dot-Product Attention 의 입력값으로 $d_k$ 차원의 query-key와 $d_v$ 차원의 value가 들어간다. 가장 먼저 query와 key의 dot product 을 계산하고, $\sqrt{d_k}$로 나눈 값을 softmax 함수를 통해 values 의 가중치 값을 구한다. 여기서 $\frac{1}{\sqrt{d_k}}$ 값을 곱해주지 않으면 additive attention 보다 성능이 떨어진다고 한다.
\[Attention(Q, K, V) = softmax(\frac{Q \cdot K^T}{\sqrt{d_k}})\cdot V\] \[MultiHead(Q, K, V ) = Concat(head_1, ..., head_h)W^{O}\] \[where \ \ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)\] \[W_i^Q \in R^{ d_{model} \times d_k}, W_i^K \in R^{d_{model} \times d_k}, W_i^V \in R^{d_{model} \times d_v}\]본 논문에서는 8 개의 head (attention) 를 사용했다. 그리고 $d_k$ = $d_v$ = $\frac{d_{model}}{h}$ = 64 를 사용했다.
Point-wise Feed forward Network
Multi-head self attention 레이어에서 출력된 값을 입력 값으로 받고, ReLU 활성함수를 사용한다. Point-wise Feed Forward Network (FFN) 의 수식은 아래와 같다 (이는 conv 1 x 1 연산을 두 번하는 것도 동일하다).
\[FFN(x) = max(0, xW_i + b_1)W_2 + b_2\]Positional Encoding
Transformer 에서는 RNN 계열의 모델을 사용하지 않기 때문에 sequence에 있는 원소들의 위치에 대한 정보도 함께 넣어줘야 한다. 그래서 Encoder와 Decoder이 시작하기 전에 positional encoding를 입력하고 embedding에 더해준다. 모델에서 위치 정보를 추가하기 위해 사용한 것은 사인과 코사인함수이다.
\[PE_{(pos,2i)}=sin\bigg(\frac{pos}{10000^{\frac{2i}{dmodel}}}\bigg)\] \[PE_{(pos,2i + 1)}=cos\bigg(\frac{pos}{10000^{\frac{2i}{dmodel}}}\bigg)\]Results
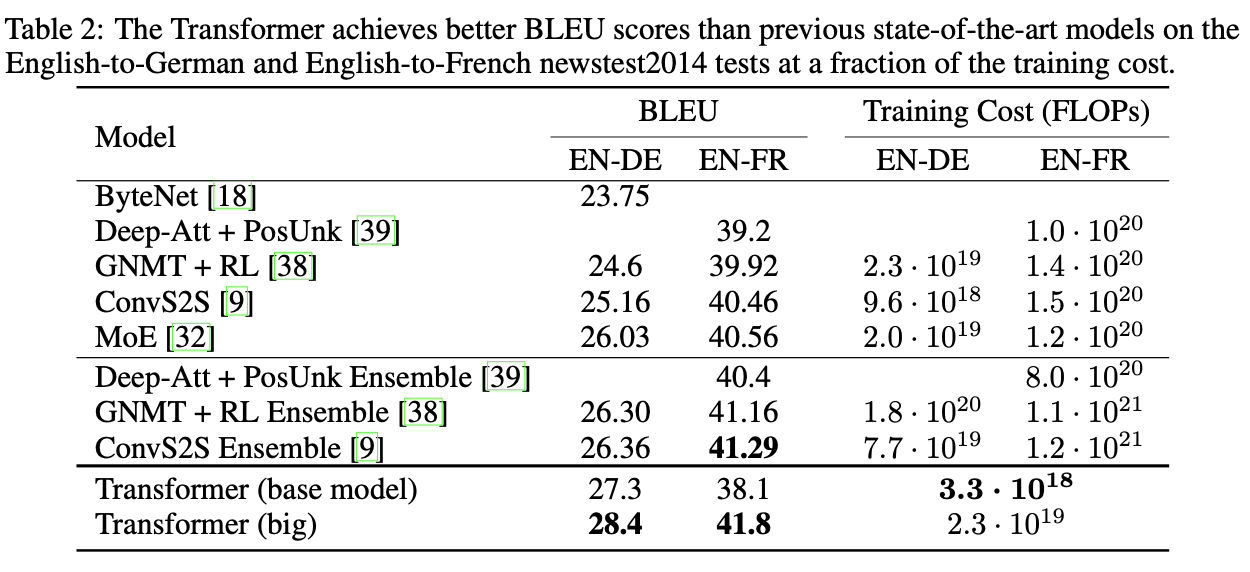
Machine Translation (EN-DE & EN-FR) 에 대한 실험 결과이다. Transformer (base model)만 봐도 EN-DE 기계번역 문제에서 가장 높은 성능을 보여줬고, 특히 Transformer (big) 은 EN-DE/EN-FR 기계번역 문제에서 모두 state-of-the-art를 수준의 성능을 보여 주었다.
Tensorflow 실습
트랜스포머 챗봇 코드: https://github.com/ukairia777/tensorflow-transformer
import pandas as pd
import urllib.request
import tensorflow_datasets as tfds
import tensorflow as tf
import time
import numpy as np
import matplotlib.pyplot as plt
import re
# urllib.request.urlretrieve("https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv", filename="ChatBotData.csv")
train_data = pd.read_csv('./ChatBotData.csv')
# 서브워드텍스트인코더를 사용하여 질문과 답변을 모두 포함한 단어 집합(Vocabulary) 생성
tokenizer = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
train_data['Q'] + train_data['A'], target_vocab_size=2**13)
# 시작 토큰과 종료 토큰에 대한 정수 부여.
START_TOKEN, END_TOKEN = [tokenizer.vocab_size], [tokenizer.vocab_size + 1]
# 시작 토큰과 종료 토큰을 고려하여 단어 집합의 크기를 + 2
VOCAB_SIZE = tokenizer.vocab_size + 2
print('시작 토큰 번호 :',START_TOKEN)
print('종료 토큰 번호 :',END_TOKEN)
print('단어 집합의 크기 :',VOCAB_SIZE)
sample_string = train_data['Q'][0]
# encode() : 텍스트 시퀀스 --> 정수 시퀀스
tokenized_string = tokenizer.encode(sample_string)
print ('정수 인코딩 후의 문장 {}'.format(tokenized_string))
# decode() : 정수 시퀀스 --> 텍스트 시퀀스
original_string = tokenizer.decode(tokenized_string)
print ('기존 문장: {}'.format(original_string))
# 최대 길이를 40으로 정의
MAX_LENGTH = 40
# 토큰화 / 정수 인코딩 / 시작 토큰과 종료 토큰 추가 / 패딩
def tokenize_and_filter(inputs, outputs):
tokenized_inputs, tokenized_outputs = [], []
for (sentence1, sentence2) in zip(inputs, outputs):
# encode(토큰화 + 정수 인코딩), 시작 토큰과 종료 토큰 추가
sentence1 = START_TOKEN + tokenizer.encode(sentence1) + END_TOKEN
sentence2 = START_TOKEN + tokenizer.encode(sentence2) + END_TOKEN
tokenized_inputs.append(sentence1)
tokenized_outputs.append(sentence2)
# 패딩
tokenized_inputs = tf.keras.preprocessing.sequence.pad_sequences(
tokenized_inputs, maxlen=MAX_LENGTH, padding='post')
tokenized_outputs = tf.keras.preprocessing.sequence.pad_sequences(
tokenized_outputs, maxlen=MAX_LENGTH, padding='post')
return tokenized_inputs, tokenized_outputs
questions, answers = tokenize_and_filter(train_data['Q'], train_data['A'])
print('질문 데이터의 크기(shape) :', questions.shape)
print('답변 데이터의 크기(shape) :', answers.shape)
# 텐서플로우 dataset을 이용하여 셔플(shuffle)을 수행하되, 배치 크기로 데이터를 묶는다.
# 또한 이 과정에서 교사 강요(teacher forcing)을 사용하기 위해서 디코더의 입력과 실제값 시퀀스를 구성한다.
BATCH_SIZE = 64
BUFFER_SIZE = 20000
# 디코더의 실제값 시퀀스에서는 시작 토큰을 제거해야 한다.
dataset = tf.data.Dataset.from_tensor_slices((
{
'inputs': questions,
'dec_inputs': answers[:, :-1] # 디코더의 입력. 마지막 패딩 토큰이 제거된다.
},
{
'outputs': answers[:, 1:] # 맨 처음 토큰이 제거된다. 다시 말해 시작 토큰이 제거된다.
},
))
dataset = dataset.cache()
dataset = dataset.shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
# 최종 버전
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, position, d_model):
super(PositionalEncoding, self).__init__()
self.pos_encoding = self.positional_encoding(position, d_model)
def get_angles(self, position, i, d_model):
angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))
return position * angles
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(
position=tf.range(position, dtype=tf.float32)[:, tf.newaxis],
i=tf.range(d_model, dtype=tf.float32)[tf.newaxis, :],
d_model=d_model)
# 배열의 짝수 인덱스(2i)에는 사인 함수 적용
sines = tf.math.sin(angle_rads[:, 0::2])
# 배열의 홀수 인덱스(2i+1)에는 코사인 함수 적용
cosines = tf.math.cos(angle_rads[:, 1::2])
angle_rads = np.zeros(angle_rads.shape)
angle_rads[:, 0::2] = sines
angle_rads[:, 1::2] = cosines
pos_encoding = tf.constant(angle_rads)
pos_encoding = pos_encoding[tf.newaxis, ...]
print(pos_encoding.shape)
return tf.cast(pos_encoding, tf.float32)
def call(self, inputs):
return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]
def scaled_dot_product_attention(query, key, value, mask):
# query 크기 : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# key 크기 : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# value 크기 : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
# padding_mask : (batch_size, 1, 1, key의 문장 길이)
# Q와 K의 곱. 어텐션 스코어 행렬.
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 스케일링
# dk의 루트값으로 나눠준다.
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 마스킹. 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은 값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치의 값은 0이 된다.
if mask is not None:
logits += (mask * -1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행된다.
# attention weight : (batch_size, num_heads, query의 문장 길이, key의 문장 길이)
attention_weights = tf.nn.softmax(logits, axis=-1)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
output = tf.matmul(attention_weights, value)
return output, attention_weights
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attention"):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
# d_model을 num_heads로 나눈 값.
# 논문 기준 : 64
self.depth = d_model // self.num_heads
# WQ, WK, WV에 해당하는 밀집층 정의
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
# WO에 해당하는 밀집층 정의
self.dense = tf.keras.layers.Dense(units=d_model)
# num_heads 개수만큼 q, k, v를 split하는 함수
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(
inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
def call(self, inputs):
query, key, value, mask = inputs['query'], inputs['key'], inputs[
'value'], inputs['mask']
batch_size = tf.shape(query)[0]
# 1. WQ, WK, WV에 해당하는 밀집층 지나기
# q : (batch_size, query의 문장 길이, d_model)
# k : (batch_size, key의 문장 길이, d_model)
# v : (batch_size, value의 문장 길이, d_model)
# 참고) 인코더(k, v)-디코더(q) 어텐션에서는 query 길이와 key, value의 길이는 다를 수 있다.
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
# 2. 헤드 나누기
# q : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# k : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# v : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용.
# (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
# (batch_size, query의 문장 길이, num_heads, d_model/num_heads)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# 4. 헤드 연결(concatenate)하기
# (batch_size, query의 문장 길이, d_model)
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
# 5. WO에 해당하는 밀집층 지나기
# (batch_size, query의 문장 길이, d_model)
outputs = self.dense(concat_attention)
return outputs
def create_padding_mask(x):
mask = tf.cast(tf.math.equal(x, 0), tf.float32)
# (batch_size, 1, 1, key의 문장 길이)
return mask[:, tf.newaxis, tf.newaxis, :]
def encoder_layer(dff, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 멀티-헤드 어텐션 (첫번째 서브층 / 셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': padding_mask # 패딩 마스크 사용
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(inputs + attention)
# 포지션 와이즈 피드 포워드 신경망 (두번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention + outputs)
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
def encoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="encoder"):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = encoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
# 디코더의 첫번째 서브층(sublayer)에서 미래 토큰을 Mask하는 함수
def create_look_ahead_mask(x):
seq_len = tf.shape(x)[1]
look_ahead_mask = 1 - tf.linalg.band_part(tf.ones((seq_len, seq_len)), -1, 0)
padding_mask = create_padding_mask(x) # 패딩 마스크도 포함
return tf.maximum(look_ahead_mask, padding_mask)
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 멀티-헤드 어텐션 (첫번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': look_ahead_mask # 룩어헤드 마스크
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두번째 서브층 / 디코더-인코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1, 'key': enc_outputs, 'value': enc_outputs, # Q != K = V
'mask': padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
def transformer(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="transformer"):
# 인코더의 입력
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")
# 인코더의 패딩 마스크
enc_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='enc_padding_mask')(inputs)
# 디코더의 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.layers.Lambda(
create_look_ahead_mask, output_shape=(1, None, None),
name='look_ahead_mask')(dec_inputs)
# 디코더의 패딩 마스크(두번째 서브층)
dec_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='dec_padding_mask')(inputs)
# 인코더의 출력은 enc_outputs. 디코더로 전달된다.
enc_outputs = encoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[inputs, enc_padding_mask]) # 인코더의 입력은 입력 문장과 패딩 마스크
# 디코더의 출력은 dec_outputs. 출력층으로 전달된다.
dec_outputs = decoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])
# 다음 단어 예측을 위한 출력층
outputs = tf.keras.layers.Dense(units=vocab_size, name="outputs")(dec_outputs)
return tf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)
small_transformer = transformer(
vocab_size = 9000,
num_layers = 4,
dff = 512,
d_model = 128,
num_heads = 4,
dropout = 0.3,
name="small_transformer")
tf.keras.utils.plot_model(
small_transformer, to_file='small_transformer.png', show_shapes=True)
def loss_function(y_true, y_pred):
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')(y_true, y_pred)
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
loss = tf.multiply(loss, mask)
return tf.reduce_mean(loss)
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps**-1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
tf.keras.backend.clear_session()
# Hyper-parameters
NUM_LAYERS = 2
D_MODEL = 256
NUM_HEADS = 8
DFF = 512
DROPOUT = 0.1
model = transformer(
vocab_size=VOCAB_SIZE,
num_layers=NUM_LAYERS,
dff=DFF,
d_model=D_MODEL,
num_heads=NUM_HEADS,
dropout=DROPOUT)
MAX_LENGTH = 40
learning_rate = CustomSchedule(D_MODEL)
optimizer = tf.keras.optimizers.Adam(
learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
def accuracy(y_true, y_pred):
# ensure labels have shape (batch_size, MAX_LENGTH - 1)
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))
return tf.keras.metrics.sparse_categorical_accuracy(y_true, y_pred)
model.compile(optimizer=optimizer, loss=loss_function, metrics=[accuracy])
EPOCHS = 5
model.fit(dataset, epochs=EPOCHS)
def evaluate(sentence):
sentence = preprocess_sentence(sentence)
sentence = tf.expand_dims(
START_TOKEN + tokenizer.encode(sentence) + END_TOKEN, axis=0)
output = tf.expand_dims(START_TOKEN, 0)
# 디코더의 예측 시작
for i in range(MAX_LENGTH):
predictions = model(inputs=[sentence, output], training=False)
# 현재(마지막) 시점의 예측 단어를 받아온다.
predictions = predictions[:, -1:, :]
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)
# 만약 마지막 시점의 예측 단어가 종료 토큰이라면 예측을 중단
if tf.equal(predicted_id, END_TOKEN[0]):
break
# 마지막 시점의 예측 단어를 출력에 연결한다.
# 이는 for문을 통해서 디코더의 입력으로 사용될 예정이다.
output = tf.concat([output, predicted_id], axis=-1)
return tf.squeeze(output, axis=0)
def preprocess_sentence(sentence):
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = sentence.strip()
return sentence
def predict(sentence):
prediction = evaluate(sentence)
predicted_sentence = tokenizer.decode(
[i for i in prediction if i < tokenizer.vocab_size])
print('Input: {}'.format(sentence))
print('Output: {}'.format(predicted_sentence))
return predicted_sentence
output = predict('영화 볼래?')
Reference:
- https://jalammar.github.io/illustrated-transformer/
- https://arxiv.org/abs/1706.03762